
8. Цифровые гуманитарные науки, Историческая информатика, Искусственный интеллект. Модели цифрового сотрудничества
| Экспериментальное электронное издание | ||||||||||||||||||||
| Преподаватель: Кирилл Фесенко | ||||||||||||||||||||
| Предыдущие лекции: | ||||||||||||||||||||
| 1. Введение в курс. План занятий | ||||||||||||||||||||
| 2. Обучение работе с онлайн-платформой для электронных коллекций | ||||||||||||||||||||
| 3. Руководство проектами и программами. Отбор материала для проектов | ||||||||||||||||||||
| 4. Создание электронных коллекций от А до Я | ||||||||||||||||||||
| 5. Работа с целевой аудиторией и продвижение электронных ресурсов | ||||||||||||||||||||
| 6. Управление изменениями | ||||||||||||||||||||
| 7. Информация, Знание, Понимание и Мудрость | ||||||||||||||||||||
|
8. Цифровые гуманитарные науки, Историческая информатика и Искусственный интеллект. Модели цифрового сотрудничества |
||||||||||||||||||||
|
Все, что мы с вами проходили на этом курсе до сегодняшнего дня, можно назвать "базовым" электронным изданием или созданием "базовых" электронных ресурсов. Оцифрованные или электронные объекты обрабатываются тем или иным способом, и публикуются/размещаются в электронных коллекциях более или менее удобным способом для дальнейшего использования исследователями. Тема сегодняшней лекции посвящена более "продвинутым" методологиям обработки материалов и их электронного издания, в основе которых лежит использование инновационных информационных и компьютерных технологий и методологий. Их правильное применение позволяет автоматизировать электронное производство, извлекать из электронного контента дополнительную пользу для исследователей, и дает им в руки "продвинутые" инструменты для работы с электронной информацией и манипуляцией ею. Данное описание этой области является наиболее общим и данным с точки зрения электронного издателя и архивиста/библиотекаря. По мере конкретизации возможностей в этой общирной области "добавленной стоимости" к базовым электронным коллекциям, и в зависимости от конкретной области знаний и практики, в которой работает тот или иной специалист (библиотекарь, историк, компьютерщик, филолог, статистик, инженер, географ и т.д.), эта тема распадается на несколько более или менее пересекающихся между собой областей, а их определения могут в большей или меньшей степени отличаться друг от друга, в зависимости от точки зрения специалиста. Сегодня я предлагаю хотя бы кратко обсудить основные, наиболее часто упоминаемые из них, - Цифровые гуманитарные науки, Историческую информатику и Искусственный интеллект - наиболее свежую модную область, которая у нас всех на слуху в последние несколько лет. |
||||||||||||||||||||
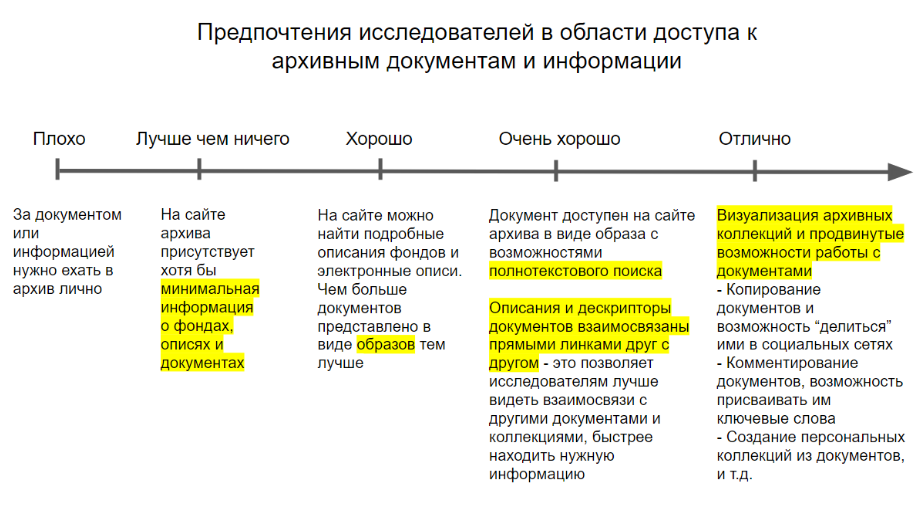
| Эту иерархию или прогрессию возможностей в области создания и развития электронных информационных ресурсов и услуг для исследователей, и продвижение от "базовых" к "продвинутым" возможностям в этой сфере, я попытался визуализировать на вот этом слайде: | ||||||||||||||||||||
 |
||||||||||||||||||||
|
Говоря об этом слайде, хотел бы отметить один важный, с моей точки зрения момент - помечая "Визуализацию архивных коллекций и другие продвинутые возможности работы с документами" (т.е. область Цифр гум наук) оценкой "Отлично", я отнюдь не имею в виду, что указанные инновационные возможности для исследователей ЛУЧШЕ или БОЛЕЕ ПОЛЕЗНЕЙ для них, чем простой но хорошо работающий веб сайт архива или библиотеки, или удобный электронный каталог и электронная библиотека с простым полнотекстовым поиском, или простая но эффективная возможность показа взаимосвязей между родственными материалами. Как раз наоборот, и это мое личное мнение, работой с продвинутыми методологиями и технологиями из области Цифр гум наук следует заниматься только после достижения качественной реализации базовых электронных ресурсов и услуг. В противном случае (с моей точки зрения, еще раз подчеркиваю это, - со мной многие могут не согласиться), забеги вперед на занятия модными (и иногда хорошо финансируемыми) проектами из области Цифр гум наук без качественной реализации базовых моделей электронного издания и создания электронные архивов и библиотек можно сравнить с попыткой усадить ваших пользователей-исследователей в космический корабль для отправки их на луну, в то время как вы еще не смогли обеспечить для них безопасность полета на простом кукурузнике. |
||||||||||||||||||||
| Предлагаю быстро пройтись по общепринятым определениям этих понятий и посмотреть на примеры проектов, методологий и инструментов из указанных областей. | ||||||||||||||||||||
|
|
||||||||||||||||||||
| Цифровые гуманитарные науки | ||||||||||||||||||||
| Цифровы́е гуманита́рные нау́ки (англ. Digital Humanities) — область исследований, обучения и созидания на стыке компьютерных и гуманитарных наук. Цифровые гуманитарные науки предполагают использование оцифрованных материалов и материалов цифрового происхождения и объединяют методологии из традиционных гуманитарных наук (история, философия, лингвистика, литература, искусство, археология, музыка и т. д.) с компьютерными науками, предоставляя компьютерные инструменты и открывая новые возможности для сбора и визуализации данных, информационного поиска, интеллектуального анализа данных, а также применения математической статистики. Исследования в этой сфере обеспечивают сохранность культурного наследия с помощью цифровых технологий, направлены на восстановление исходного материала, используя компьютерные программы, а также усовершенствование методов анализа данных, их структурирования и доступа к информации. Результаты дают возможность поднимать новые вопросы и использовать новые подходы к изучению гуманитарных наук.(Википедия) См. также: Манифест Digital Humanities (2010 г.) | ||||||||||||||||||||
| Основные методы и направления исследований и разработок в Цифр гум науках | ||||||||||||||||||||
| Та же Википедия указывает следующие: | ||||||||||||||||||||
|
||||||||||||||||||||
| Публикация данных в свободный доступ, инициатива TEI (Text encoding initiative, www.tei-c.org) касающаяся разработки и представления текста в электронной форме и декодирующих методов, которые делают текст «читаемым» и пригодным для машинной обработки в гуманитарных, лингвистических и социальных науках. | ||||||||||||||||||||
| Примеры проектов: | ||||||||||||||||||||
|
||||||||||||||||||||
| Развитие супер-компьютеров и компьютерных мощностей, умные города (smart cities), облачные вычисления (англ. cloud computing), Интернет вещей (Internet of things), электронная коммерция (e-commerce) и др. | ||||||||||||||||||||
| Примеры проектов: | ||||||||||||||||||||
|
||||||||||||||||||||
| Создание больших объединенных коллекций из оцифрованных или электронных материалов, поддерживаемых группами организаций-участников проекта. Коллективно решаются вопросы организации баз данных, качества данных, организации структуры данных, недостатков описания, преодоления ограничений авторских прав для научных целей, корректного визуального отображения, создания и поддержки сообщества энтузиастов вокруг проекта. | ||||||||||||||||||||
| Примеры проектов: | ||||||||||||||||||||
| HathiTrust - объединяет электронные копии более трех миллионов исследовательских записей (книги, отчеты, публикации и другие документы), доступных для чтения и полнотекстового поиска, и аккумулированных из 60 научных библиотек США | ||||||||||||||||||||
|
|
||||||||||||||||||||
|
||||||||||||||||||||
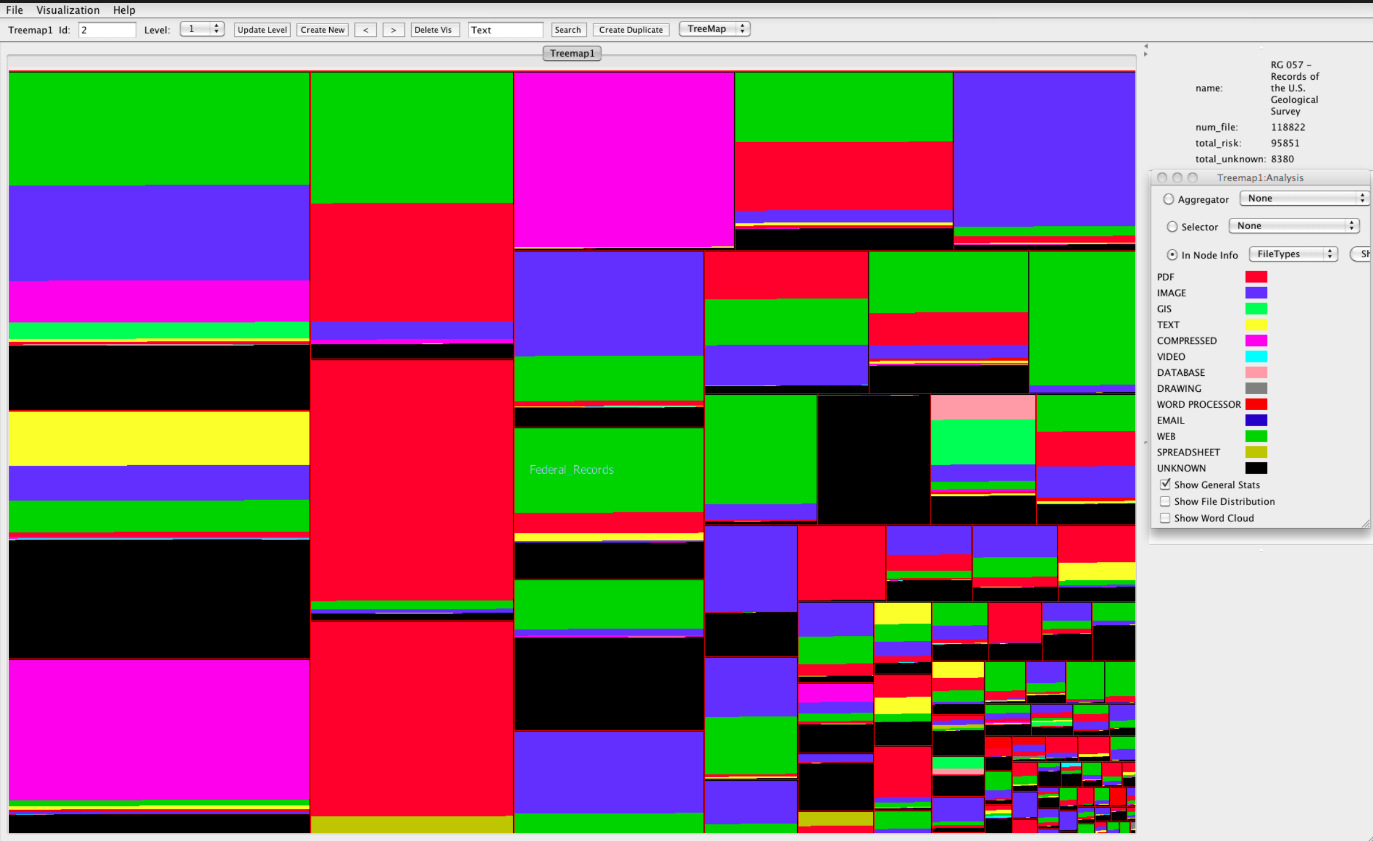
| Позволяет создать наглядное суммарное представление об объекте путем соединения различных типов данных, например, времени и характеристик. Также в цифровых гуманитарных науках визуализация облегчает запоминание, позволяет быстро оценить данные, способствует распространению и популяризации знания. | ||||||||||||||||||||
| Примеры визуализации архивных коллекций: | ||||||||||||||||||||
 |
||||||||||||||||||||
Взгляд на архивы будущего (Сообщение американского Национального научного фонда)(Заметка подготовлена К. Фесенко для Вестника массовой оцифровки в 2011 г.)
|
||||||||||||||||||||
|
|
||||||||||||||||||||
|
||||||||||||||||||||
| Вовлечение интернет-пользователей к участию в научной деятельности и развитии проектов | ||||||||||||||||||||
| Примеры проектов: | ||||||||||||||||||||
| The Great War Archive: A Community Collection | ||||||||||||||||||||
|
||||||||||||||||||||
| Going to the Show. https://dhprojects.web.unc.edu/going-to-the-show/ - исчез из Интернета! | ||||||||||||||||||||
| См. список проектов Лаборатории цифр гумн наук Университета Северной Каролины | ||||||||||||||||||||
| Историческая информатика | ||||||||||||||||||||
| Истори́ческая информа́тика — междисциплинарная область исторических исследований, целью которой является расширение информационного, методического и технологического обеспечения исторической науки, а также апробация новых информационных технологий и методов в конкретно-исторических исследованиях. В основе исторической информатики лежит совокупность теоретических и прикладных знаний, необходимых для создания, обработки и анализа оцифрованных исторических источников всех видов. (Википедия) | ||||||||||||||||||||
| См. материалы Ассоциации "История и компьютер": Наши состоявшиеся проекты -- Наши проекты в разработке | ||||||||||||||||||||
| Искусственный интеллект | ||||||||||||||||||||
|
Свойство искусственных интеллектуальных систем выполнять творческие функции, которые традиционно считаются прерогативой человека; наука и технология создания интеллектуальных машин, особенно интеллектуальных компьютерных программ. Другие определения искусственного интеллекта из Википедии: - Научное направление, в рамках которого ставятся и решаются задачи аппаратного или программного моделирования тех видов человеческой деятельности, которые традиционно считаются интеллектуальными. |
||||||||||||||||||||
| Из выстуления Кирилл Фесенко. Архивы и Искусственный интеллект. Выступление на Конгрессе молодых ученых (1-3 декабря 2022 г., Федеральная территория "Сириус"): | ||||||||||||||||||||
|
В последние годы ИИ привлекает особенно повышенный интерес, включая в области его применения в архивах. Работа здесь идет в разных направлениях, и соответственно специалисты дают иногда разные определения ИИ в зависимости от их конкретных направлений исследований и разработок. В частности, среди популярных направлений можно упомянуть:
При всем при этом следует оговориться, что разные программы Искусственного Интеллекта показывают результаты разного качества, которые кого то побуждают еще более активно исследовать и улучшать работу в этом направлении, а кого то укрепляют в их скептицизме.
Новые возможности здесь кажутся захватывающими - я также не смог удержаться и попробовал работу программы DALLE 2 для производства двух иллюстраций, которые мне потребовались для выступления на другой конференции в прошлом месяце.
Но возвращаясь все же к вопросу об улучшении доступа исследователей к архивным коллекциям и цифровой трансформации архивов в следующее десятилетие, хотел бы упомянуть некоторые проблемы, разрешение которых более чем искусственного интеллекта потребует живого человеческого интеллекта, смекалки и инициативы архивных специалистов. В частности, речь идет о таких характерных проблемах в архивной отрасли как:
Что меня здесь беспокоит, в частности, так это выбор приоритетов для расходования весьма ограниченных ресурсов, которые направляются на развитие архивной системы и улучшения доступа к ней исследователей. Нам необходимо убедиться, что за занятиями популярными веяниями, в частности в области ИИ, мы не на минуту не ослабим внимания к важным текущим потребностям исследователей. |
||||||||||||||||||||
|
10 апреля 2023 года ВНИИДАД провел круглый стол по теме «Практические задачи внедрения технологий искусственного интеллекта в деятельность архивов». |
||||||||||||||||||||
| - Об основных направлениях применения ИИ в архивном деле. ст.н.с. ВНИИДАД, старший преподаватель кафедры «Международный транспортный менеджмент и управление цепями поставок» РУТ (МИИТ), Е.В. Боброва последовательно показала, в каких направлениях архивной работы возможно и полезно применение технологий искусственного интеллекта. Вместе с тем были названы основные проблемы на пути внедрения ИИ, среди которых – формирование нормативной базы, доверие к информации, которую генерирует ИИ, методическое обеспечения создания и развития прикладных видов ИИ. | ||||||||||||||||||||
| - Опыт внедрения искусственного интеллекта в работу учреждения архивной отрасли Санкт-Петербурга. Председатель Архивного комитета Санкт-Петербурга, П.Е. Тищенко. представил два проекта по применению ИИ, решающих актуальные задачи работы ЦГАКФФД СПб и ЛОСДГАУ СПб | ||||||||||||||||||||
| - Особенности применения системы протоколирования совещания «Нестор.BRIEF». директор по развитию бизнеса группы компаний ЦРТ О.А. Глебова М.М. Коваленко. Продемонстрированы способы распознавания и создания описаний фонодокументов на примере фонда Ленинградского дома радио | ||||||||||||||||||||
| - Применение гиперспектральных технологий для восстановления угасающего текста документов и печатных изданий, а также для оценки их биозараженности. | ||||||||||||||||||||
| + еще с десяток докладов. См. запись докладов по адресу: https://youtu.be/KHzhpS42vqk | ||||||||||||||||||||
| "Список пожеланий для платформы ИнфоРост" (К.Фесенко, 2009-2014 гг.) | ||||||||||||||||||||
| Models of Digital Cooperation - Макет сводной ЭБ - Первый пилот | ||||||||||||||||||||
| "Карта советской литературы". Описание проекта |






